Scale your
Security Testing
Extend testing capabilities to suit your IT and security requirements. Our crowdsourced, platform-driven model provides the experts you need, when you need them, in a few clicks.
Global Bug Bounty & Vulnerability
Management Platform
Extend testing capabilities to suit your IT and security requirements. Our crowdsourced, platform-driven model provides the experts you need, when you need them, in a few clicks.
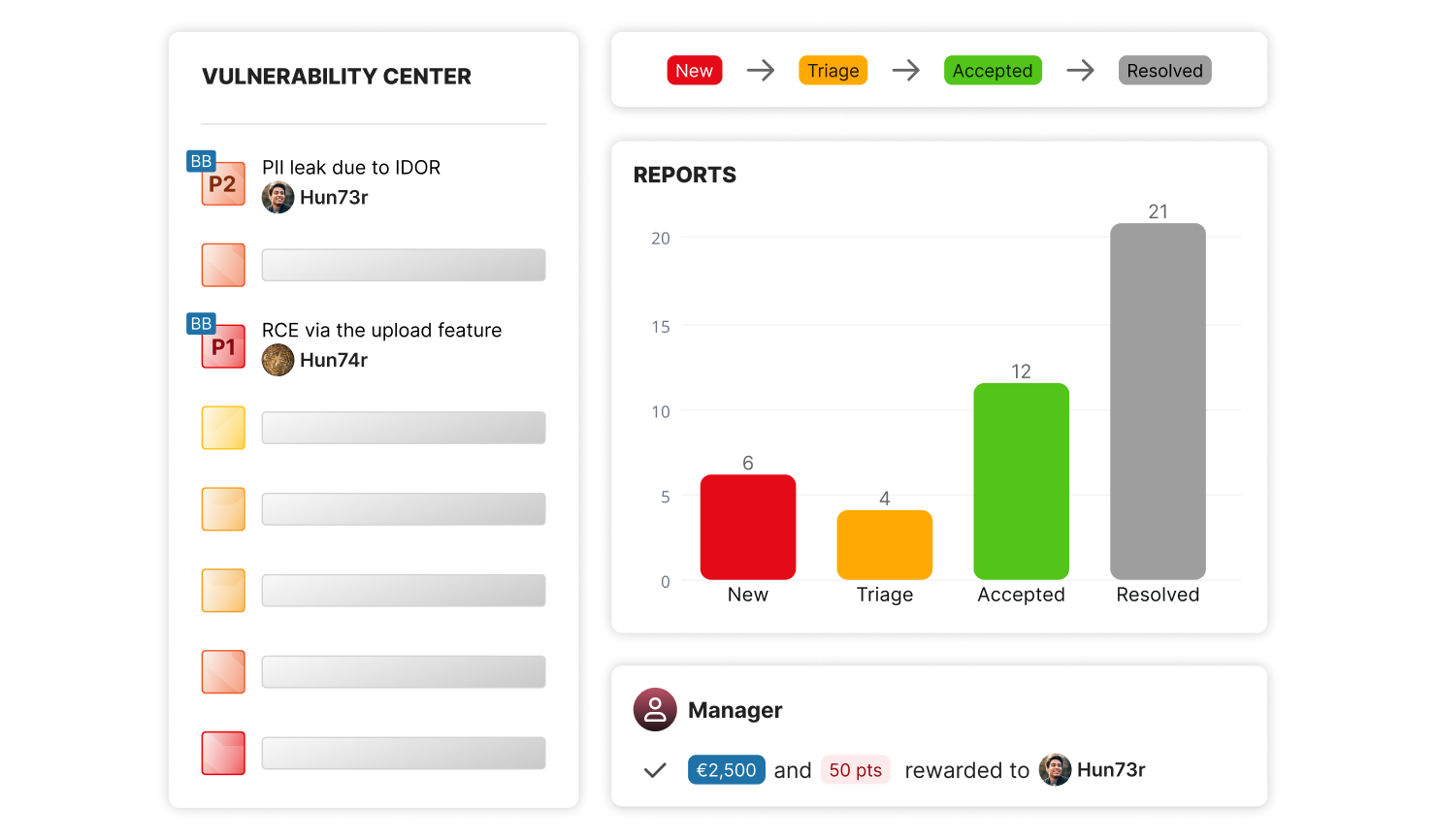
Pay only for targeted, valuable and actionable reports. Streamline your vulnerability management workflow through integrations, automation and collaboration-friendly features.
Multi-channel vulnerability reporting denies CISOs a global overview of cyber risks. Manage vulnerabilities from all sources – including Bug Bounty, VDPs, pentests and scanners – through our unified interface.
Leverage the skillsets of tens of thousands of fully vetted ethical hackers – experts at finding critical vulnerabilities in your online assets. Benefit from a crowdsourced, platform-driven and pay-for-results approach to security testing and align vulnerability assessment to your security, IT and business requirements.
“With the evolving nature of data security, as well as the aggressive nature of hackers who exploit technology to steal data, we believe in working with the larger cybersecurity community to strengthen our IT ecosystems.”
“Bug Bounty is becoming a security standard because it’s the way to take your vulnerability research to scale. You need to start small, but to start now!”
“Bug Bounty is a matter of being smart: attack yourself before anyone else does, because at the end of the day, bad actors will not tell you what vulnerabilities you have.”
With the evolving nature of data security, as well as the aggressive nature of hackers who exploit technology to steal data, we believe in working with the larger cybersecurity community to strengthen our IT ecosystems.
ADOPT A PROACTIVE SECURITY POSTURE NOW
Harness the power of crowdsourced security to supercharge the discovery and remediation of vulnerabilities.